This is the first blog of the 6D pose estimation series. Here I write a summary of the paper “Real-Time Seamless Single Shot 6D Object Pose prediction” from CVPR 2018. In addition, it is one of my assignments of the course “Visual Media Engineering” at the University of Tokyo.
Introduction:
This paper introduces a single-shot approach for simultaneously detecting an object in an RGB image and predicting its 6D pose without requiring multiple stages or having to examine multiple hypotheses. This method is accurate enough not to require additional post-processing.
The key component of this method is a new CNN architecturethat directly predicts the 2D image locations of the projected vertices ofthe object’s 3D bounding box. The object’s 6D pose is then estimated using a PnP algorithm.
Model:
Parameterize the 3D model of each object with 9 control points. For these control points, they select the 8 corners of the tight 3D bounding box fitted to the 3D model. In addition, they use the centroid of the object’s 3D model as the 9th point.
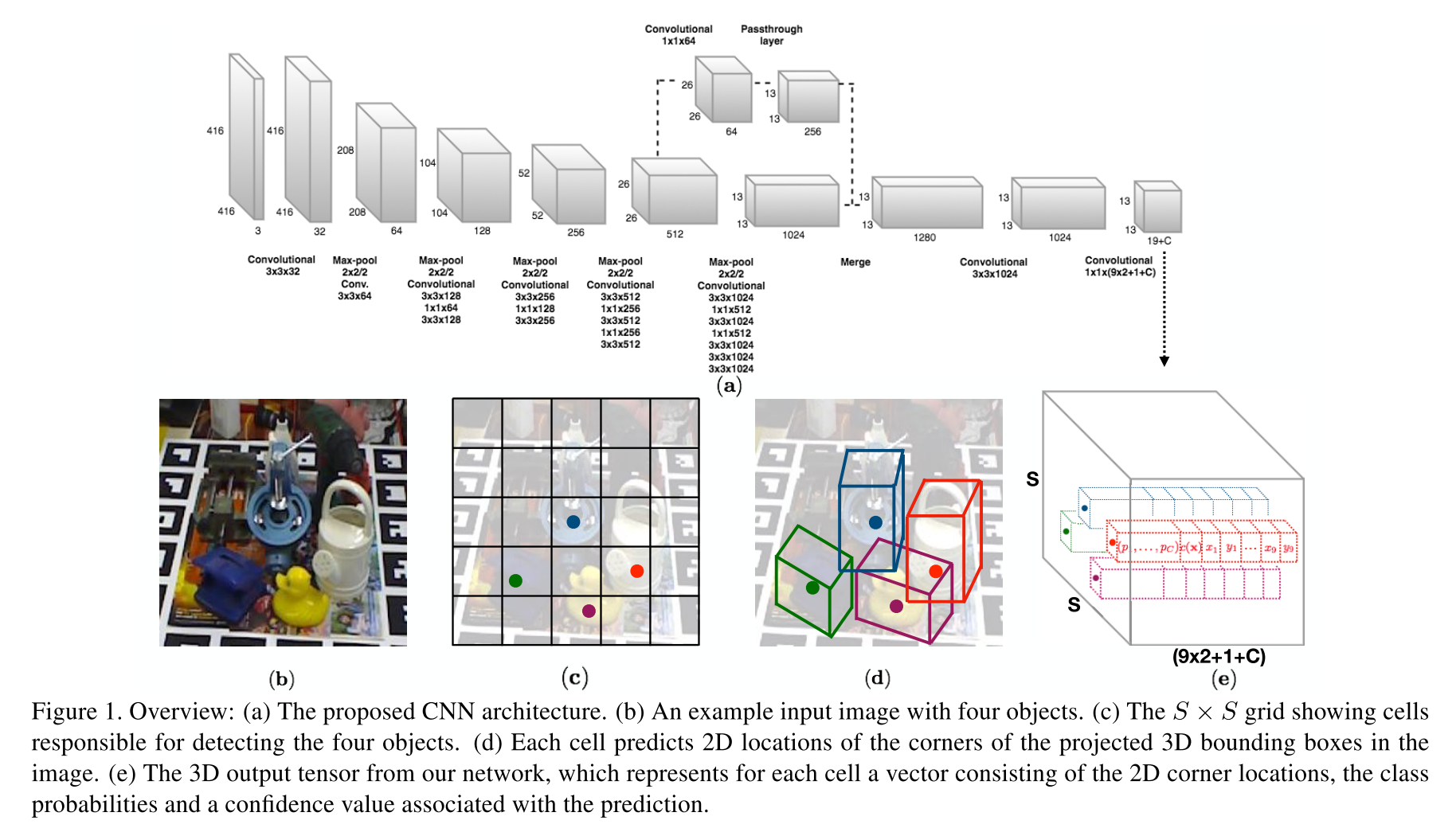
This model takes as input a single full color image, processes it with a fully-convolutional architecture shown in Figure 1(a) and divides the image into a 2D regular grid containing S × S cells as shown in Figure 1(c). In their model, each grid location in the 3D output tensor will be associated with a multidimensional vector, consisting of predicted 2D image locations of the 9 control points, the class probabilities of the object and an overall confidence value.
The output target values for the network are stored in a 3D tensor of size S × S × D visualized in Fig. 1(e). Here, it should be D = 9×2+C+1 , because we have 9 (xi, yi) control points, C class probabilities and one confidence value.
The predicted confidence value is modeled using a confidence function shown in Figure 2. The confidence function, c(x), returns a confidence value for a predicted 2D point denoted by x based on its distance DT(x) from the ground truth i.e. target 2D point.

The distance DT(x) is defined as the 2D Euclidean distance in the image space. In practice, the confidence function of all the control points are calculated to the mean value and assigned as the confidence value

Contribution of this paper:
Previous CNN arthitectures like BB8 use one CNN to coarsely segment the object and another to predict the 2D locations of the projections of the object’s 3D bounding box given the segmentation, which are then used to compute the 6D pose using a PnP algorithm. There are two steps befroe pnp to generate the 2D location of the bounding box. Due to the multi-stage, this kind of approches has a low calculation velocity. While for the CNN architure in this paper, it can detect the object and calculate poses simutaneously in one CNN network, hence reduce the calculation time.
Previous CNN architectures like BB8 and and SSD-6D require a further pose refinement step for improved accuracy, which increases their running times linearly with the number of objects being detected. In this paper, the method is accurate even without any a posteriori refinement.
Moreover, this CNN architecture doesn’t need a precise and detailed textured 3D object model. Only the 3D bounding box of the object shape is required for training.
Reference:
B. Tekin, S. N. Sinha and P. Fua, “Real-Time Seamless Single Shot 6D Object Pose Prediction,” 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, 2018, pp. 292-301, doi: 10.1109/CVPR.2018.00038.